
आज के इस इंटरनेट युग में किसी भी विषय पर जानकारी जुटाने और उस पर शोध करने के लिए हर कोई गूगल का रुख करता है| गूगल पर उस विषय से संबंधित कुछ शब्द लिख कर अपेक्षा करता है कि गूगल उसे उस विषय पर विशेषज्ञों के लिखे ज्ञानपूर्ण लेखों से जोड़ेगा |
लेकिन सारा ज्ञान क्या इस इन्टरनेट के वेबपृष्ठों में ही उपलब्ध है?
उन अनगिनत पुस्तकों, पत्रिकाओं, समाचार पत्रों इत्यादि का क्या, जिसमें हमारे से पहले वाली पीढ़ी ने हमारे लिए न जाने कितने ही ज्ञान-विज्ञान के खज़ाने और साहित्यिक, बोद्धिक धरोहर इत्यादि को हमारे लिए सहेज कर छोड़ा है?
क्या गूगल सर्च से हम उस तक पहुँच पाएंगे?
आज तक तो यह ख्वाब मुश्किल ही लगता था, लेकिन गूगल की निम्न तकनीक से इस दिशा में आशा की नई किरण नजर आ रही है|
इस तकनीक का नाम है, OCR – Optical Character Recognization ( ऑप्टिकल करैक्टर रेकोगानाईजेशन)
इस तकनीक के माध्यम से हम उन सभी पुस्तकों में छपे अक्षरों को इन्टरनेट के पृष्ठों पर अंकित कर सकेंगे जो अभी तक सिर्फ किसी पुस्तकालय और अलमारी में जीर्ण-शीर्ण अवस्था में पड़े अपने आखिरी दिन गिन रहे थे| इससे किसी भी पन्ने पर छपे शब्दों और उसकी भाषा को समझ उसे डिजिटल रूप में कंप्यूटर और इन्टरनेट पर सहेजा जा सकेगा |
हालाँकि यह तकनीक सिर्फ गूगल की नहीं है, पर गूगल न इस तकनीक को सभी लोगों के लिए कैसे सुलभ करवाया है, यह हम जानेंगे | गूगल ने अपने “शोध” ब्लॉग पर इस बारे में इस लिंक पर लिखा है |
गूगल द्वारा उपलब्ध करवाई जा रही इस सुविधा का उदाहरण :
मेरे पास एक पत्रिका का पीडीऍफ़ स्कैन था, लेकिन मैं उसके शब्दों को न ही कॉपी या एडिट कर सकता था, न ही गूगल उस पत्रिका के शब्दों को मेरे लिए खोज ही सकता था |
आइये देखते है कि कैसे हम उस पत्रिका में छपे हिंदी शब्दों को सामान्य डिजिटल टेक्स्ट में परिवर्तित कर सकते है,
१. इसके लिए मैंने इस पत्रिका के एक अंश को चुना :

२. इस अंश को मैंने इस इमेज/फोटो के रूप से सहेज लिया

३. इसके बाद मैंने इस फोटो को “गूगल ड्राइव” पर अपलोड कर लिया
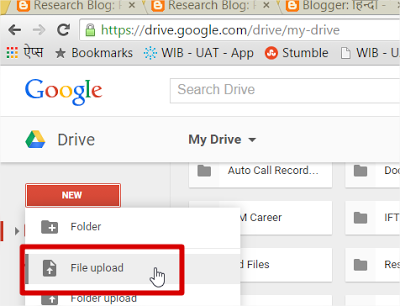
४. उसके बाद गूगल ड्राइव में जाकर उस फोटो पर “राईट क्लिक” किया और इसे “गूगल डॉक्” के साथ खोलने के लिए क्लिक कर दिया

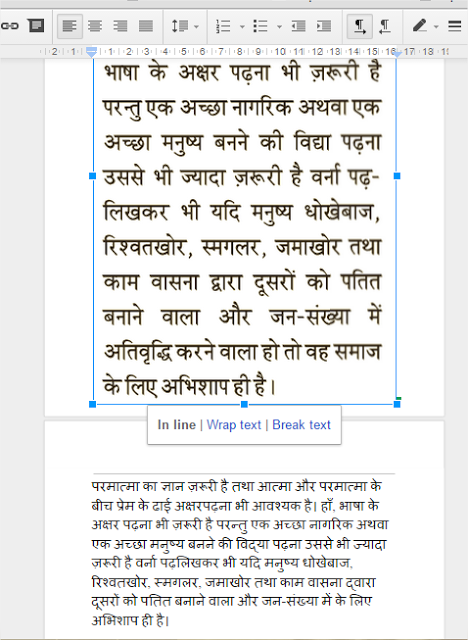
हालाँकि गूगल की यह तकनीक अभी अपने शुरुआती दौर में है, और हो सकता है कुछ मामलों में आपको सही हिंदी टेक्स्ट न दिखा पाए|
लेकिन फिर भी यदि आपके पास हिंदी की कोई पुस्तक हार्ड कॉपी के रूप में है, तो आप अपने मोबाइल के कैमरे से उसके फोटो खींच कर इस सुविधा से उसके शब्दों को इस डिजिटल दुनिया में ला सकते है|
यदि आने वाले समय में इस तकनीक के उपयोग से पुरानी पुस्तकों के पन्नो में सिमटा सम्पूर्ण भारतीय साहित्य इन्टरनेट पर उपलब्ध हो जाये तो यह देश, भाषा और मानवता की बड़ी सेवा होगी |